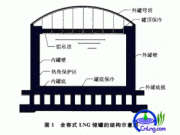
[Р§7.14]НЋвдЩЯНЈСЂСДБэЃЌЩОГ§НсЕуЃЌВхШыНсЕуЕФКЏЪ§зщжЏдквЛЦ№ЃЌдйНЈвЛИіЪфГіШЋВПНсЕуЕФКЏЪ§ЃЌШЛКѓгУmainКЏЪ§ЕїгУЫќУЧЁЃ
#define NULL 0
#define TYPE struct stu
#define LEN sizeof(struct stu)
struct stu
{
int num;
int age;
struct stu *next;
};
TYPE * creat(int n)
{
struct stu *head,*pf,*pb;
int i;
for(i=0;i<n;i++)
{
pb=(TYPE *)malloc(LEN);
printf("input Number and Age\n");
scanf("%d%d",&pb->num,&pb->age);
if(i==0)
pf=head=pb;
else pf->next=pb;
pb->next=NULL;
pf=pb;
}
return(head);
}
TYPE * delete(TYPE * head,int num)
{
TYPE *pf,*pb;
if(head==NULL)
{ printf("\nempty list!\n");
goto end;}
pb=head;
while (pb->num!=num && pb->next!=NULL)
{pf=pb;pb=pb->next;}
if(pb->num==num)
{ if(pb==head) head=pb->next;
else pf->next=pb->next;
printf("The node is deleted\n"); }
else
free(pb);
printf("The node not been found!\n");
end:
return head;
}
TYPE * insert(TYPE * head,TYPE * pi)
{
TYPE *pb ,*pf;
pb=head;
if(head==NULL)
{ head=pi;
pi->next=NULL; }
else
{
while((pi->num>pb->num)&&(pb->next!=NULL))
{ pf=pb;
pb=pb->next; }
if(pi->num<=pb->num)
{ if(head==pb) head=pi;
else pf->next=pi;
pi->next=pb; }
else
{ pb->next=pi;
pi->next=NULL; }
}
return head;
}
void print(TYPE * head)
{
printf("Number\t\tAge\n");
while(head!=NULL)
{
printf("%d\t\t%d\n",head->num,head->age);
head=head->next;
}
}
main()
{
TYPE * head,*pnum;
int n,num;
printf("input number of node: ");
scanf("%d",&n);
head=creat(n);
print(head);
printf("Input the deleted number: ");
scanf("%d",&num);
head=delete(head,num);
print(head);
printf("Input the inserted number and age: ");
pnum=(TYPE *)malloc(LEN);
scanf("%d%d",&pnum->num,&pnum->age);
head=insert(head,pnum);
print(head);
}
ЁЁЁЁБОР§жаЃЌprintКЏЪ§гУгкЪфГіСДБэжаИїИіНсЕуЪ§ОнгђжЕЁЃКЏЪ§ЕФаЮВЮheadЕФГѕжЕжИЯђСДБэЕквЛИіНсЕуЁЃдкwhileгяОфжаЃЌЪфГіНсЕужЕКѓЃЌheadжЕБЛИФБфЃЌжИЯђЯТвЛНсЕуЁЃШєБЃСєЭЗжИеыheadЃЌ дђгІСэЩшвЛИіжИеыБфСПЃЌАбheadжЕИГгшЫќЃЌдйгУЫќРДЬцДњheadЁЃдкmainКЏЪ§жаЃЌnЮЊНЈСЂНсЕуЕФЪ§ФПЃЌ numЮЊД§ЩОНсЕуЕФЪ§ОнгђжЕЃЛheadЮЊжИЯђСДБэЕФЭЗжИеыЃЌpnumЮЊжИЯђД§ВхНсЕуЕФжИеыЁЃ mainКЏЪ§жаИїааЕФвтвхЪЧЃК
ЕкСљааЪфШыЫљНЈСДБэЕФНсЕуЪ§ЃЛ
ЕкЦпааЕїcreatКЏЪ§НЈСЂСДБэВЂАбЭЗжИеыЗЕЛиИјheadЃЛ
ЕкАЫааЕїprintКЏЪ§ЪфГіСДБэЃЛ
ЕкЪЎааЪфШыД§ЩОНсЕуЕФбЇКХЃЛ
ЕкЪЎвЛааЕїdeleteКЏЪ§ЩОГ§вЛИіНсЕуЃЛ
ЕкЪЎЖўааЕїprintКЏЪ§ЪфГіСДБэЃЛ
ЕкЪЎЫФааЕїmallocКЏЪ§ЗжХфвЛИіНсЕуЕФФкДцПеМфЃЌ ВЂАбЦфЕижЗИГгшpnum;
ЕкЪЎЮхааЪфШыД§ВхШыНсЕуЕФЪ§ОнгђжЕЃЛ
ЕкЪЎСљааЕїinsertКЏЪ§ВхШыpnumЫљжИЕФНсЕуЃЛ
ЕкЪЎЦпаадйДЮЕїprintКЏЪ§ЪфГіСДБэЁЃ
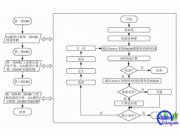
ЁЁЁЁДгдЫааНсЙћПДЃЌЪзЯШНЈСЂЦ№3ИіНсЕуЕФСДБэЃЌВЂЪфГіЦфжЕЃЛдйЩО103КХНсЕуЃЌжЛЪЃЯТ105ЃЌ108КХНсЕуЃЛгжЪфШы106КХНсЕуЪ§ОнЃЌ ВхШыКѓСДБэжаЕФНсЕуЮЊ105ЃЌ106ЃЌ108ЁЃСЊКЯЁАСЊКЯЁБвВЪЧвЛжжЙЙдьРраЭЕФЪ§ОнНсЙЙЁЃ дквЛИіЁАСЊКЯЁБФкПЩвдЖЈвхЖржжВЛЭЌЕФЪ§ОнРраЭЃЌ вЛИіБЛЫЕУїЮЊИУЁАСЊКЯЁБРраЭЕФБфСПжаЃЌдЪаэзАШыИУЁАСЊКЯЁБЫљЖЈвхЕФШЮКЮвЛжжЪ§ОнЁЃ етдкЧАУцЕФИїжжЪ§ОнРраЭжаЖМЪЧАьВЛЕНЕФЁЃР§ШчЃЌ ЖЈвхЮЊећаЭЕФБфСПжЛФмзАШыећаЭЪ§ОнЃЌЖЈвхЮЊЪЕаЭЕФБфСПжЛФмИГгшЪЕаЭЪ§ОнЁЃ
ЁЁЁЁдкЪЕМЪЮЪЬтжагаКмЖретбљЕФР§згЁЃ Р§ШчдкбЇаЃЕФНЬЪІКЭбЇЩњжаЬюаДвдЯТБэИёЃК ае Ућ Фъ Сф жА вЕ ЕЅЮЛ ЁАжАвЕЁБвЛЯюПЩЗжЮЊЁАНЬЪІЁБКЭЁАбЇЩњЁБСНРрЁЃ ЖдЁАЕЅЮЛЁБвЛЯюбЇЩњгІЬюШыАрМЖБрКХЃЌНЬЪІгІЬюШыФГЯЕФГНЬбаЪвЁЃ АрМЖПЩгУећаЭСПБэЪОЃЌНЬбаЪвжЛФмгУзжЗћРраЭЁЃ вЊЧѓАбетСНжжРраЭВЛЭЌЕФЪ§ОнЖМЬюШыЁАЕЅЮЛЁБетИіБфСПжаЃЌ ОЭБиаыАбЁАЕЅЮЛЁБЖЈвхЮЊАќКЌећаЭКЭзжЗћаЭЪ§зщетСНжжРраЭЕФЁАСЊКЯЁБЁЃ
ЁЁЁЁЁАСЊКЯЁБгыЁАНсЙЙЁБгавЛаЉЯрЫЦжЎДІЁЃЕЋСНепгаБОжЪЩЯЕФВЛЭЌЁЃдкНсЙЙжаИїГЩдБгаИїздЕФФкДцПеМфЃЌ вЛИіНсЙЙБфСПЕФзмГЄЖШЪЧИїГЩдБГЄЖШжЎКЭЁЃЖјдкЁАСЊКЯЁБжаЃЌИїГЩдБЙВЯэвЛЖЮФкДцПеМфЃЌ вЛИіСЊКЯБфСПЕФГЄЖШЕШгкИїГЩдБжазюГЄЕФГЄЖШЁЃгІИУЫЕУїЕФЪЧЃЌ етРяЫљЮНЕФЙВЯэВЛЪЧжИАбЖрИіГЩдБЭЌЪБзАШывЛИіСЊКЯБфСПФкЃЌ ЖјЪЧжИИУСЊКЯБфСППЩБЛИГгшШЮвЛГЩдБжЕЃЌЕЋУПДЮжЛФмИГвЛжжжЕЃЌ ИГШыаТжЕдђГхШЅОЩжЕЁЃШчЧАУцНщЩмЕФЁАЕЅЮЛЁББфСПЃЌ ШчЖЈвхЮЊвЛИіПЩзАШыЁААрМЖЁБЛђЁАНЬбаЪвЁБЕФСЊКЯКѓЃЌОЭдЪаэИГгшећаЭжЕЃЈАрМЖ)ЛђзжЗћДЎЃЈНЬбаЪв)ЁЃвЊУДИГгшећаЭжЕЃЌвЊУДИГгшзжЗћДЎЃЌВЛФмАбСНепЭЌЪБИГгшЫќЁЃСЊКЯРраЭЕФЖЈвхКЭСЊКЯБфСПЕФЫЕУївЛИіСЊКЯРраЭБиаыОЙ§ЖЈвхжЎКѓЃЌ ВХФмАбБфСПЫЕУїЮЊИУСЊКЯРраЭЁЃ